
ML边缘部署
Table of Contents
问题#
- 如何计算模型的参数量
- 为什么某些方法可以降低参数量
- 如何估计一个大规模网络能否部署
- 部署后如何评定是否可以使用,有什么参数(能量/延迟时间)
如何计算模型的参数量#
CNN 模型参数如何估计#
见ML hardware 那门 MIT 的课
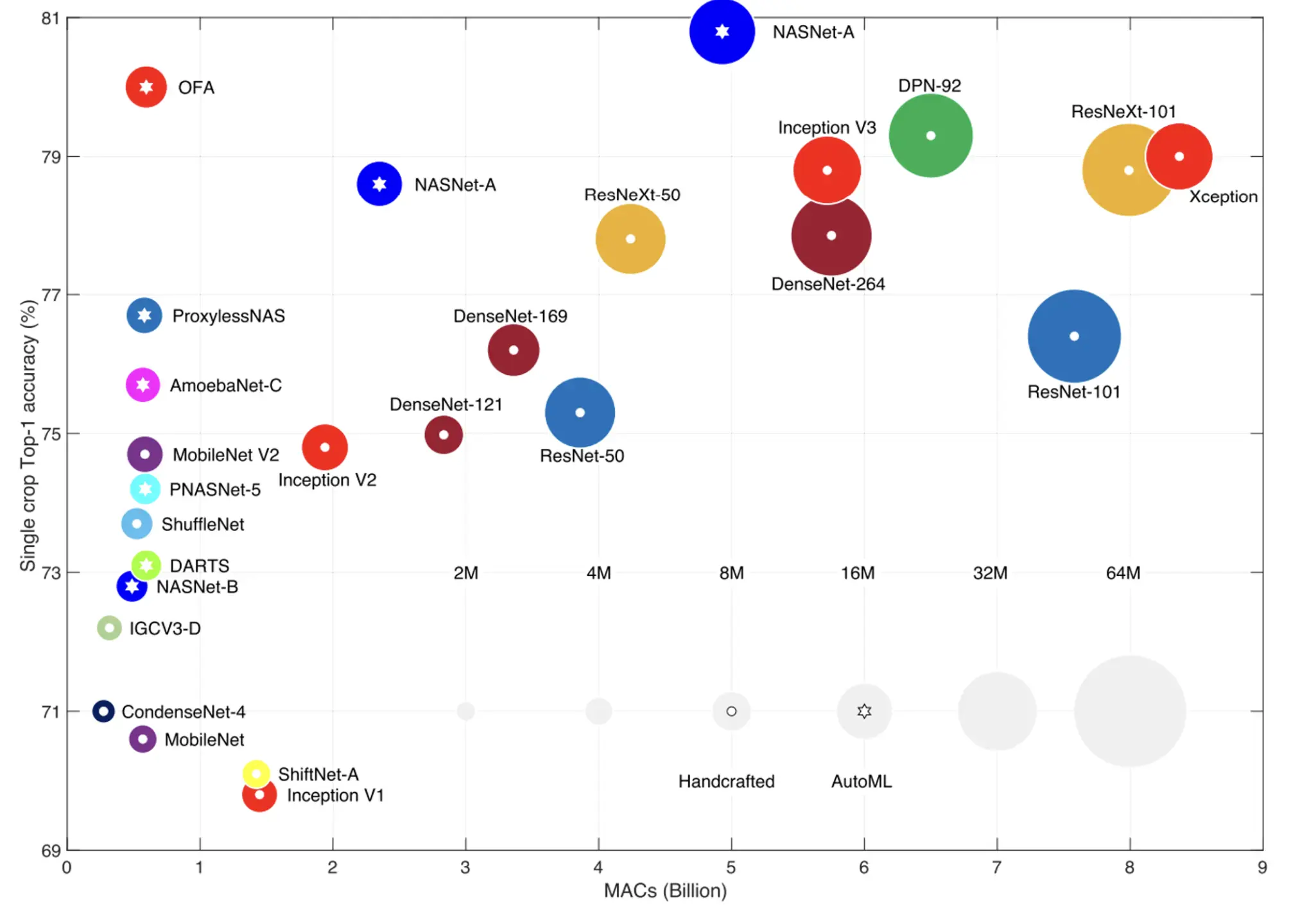
著名的网络规模与网络大小#
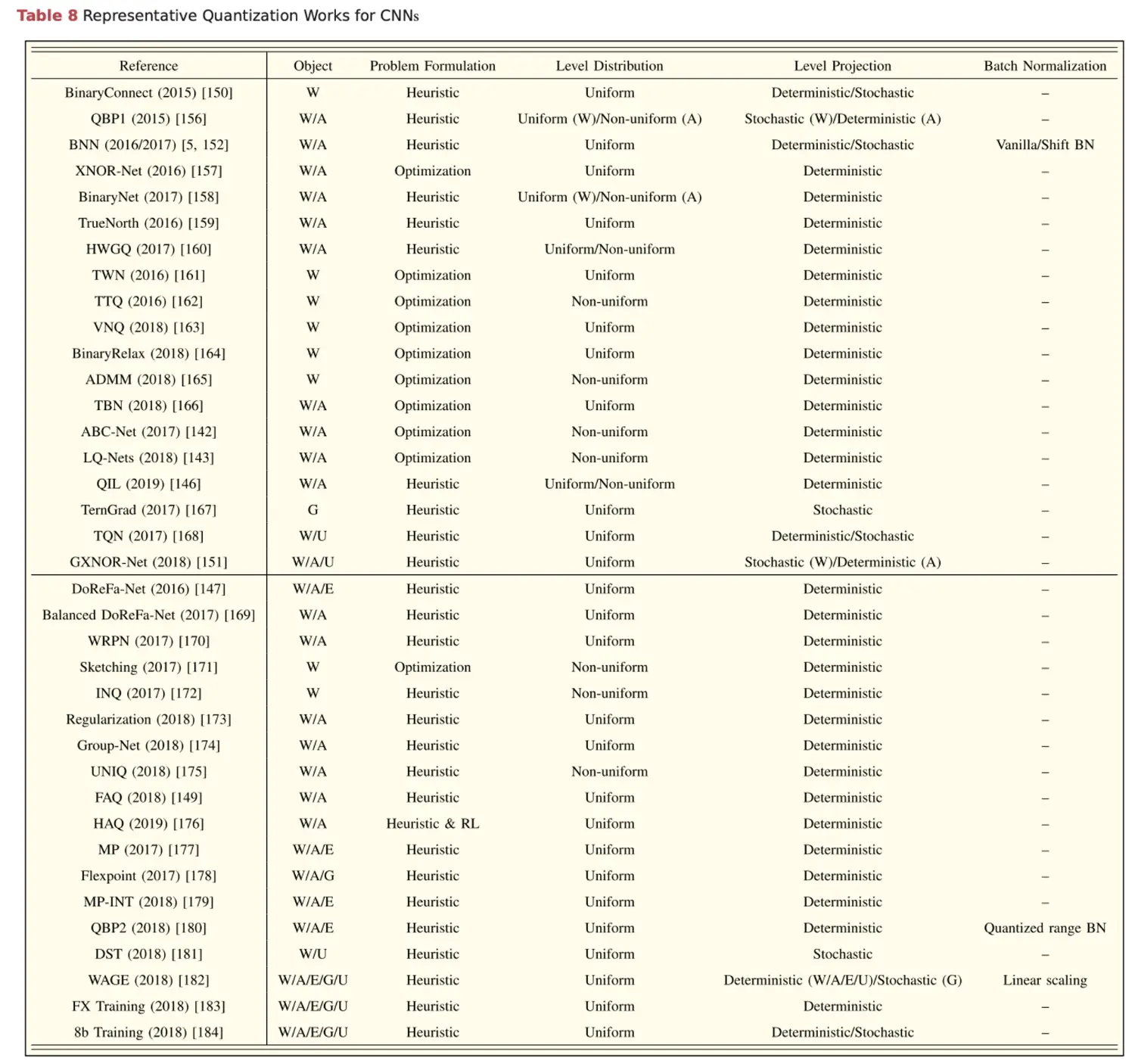
一些对 CNN 的量化方法。
来自Han Song 老师的 review
为什么某些方法可以降低参数量#
量化为8位的图像识别网络大小#
- 内存限制:STM32微控制器的RAM通常在几十KB到几MB不等。例如,一些低端型号可能只有20KB RAM,而高端型号可达1MB或更多。
- 模型大小:量化为8位的网络模型大小显著小于未量化的模型。量化不仅减少了权重的存储需求,还简化了计算。一般来说,一个简单的量化图像识别网络(例如基于简化的卷积神经网络)可以被设计成几百KB大小。
使用Depthwise Conv2D的情况#
使用Depthwise Conv2D(深度可分离卷积)可以进一步减少模型的大小和计算需求。Depthwise Conv2D将标准的卷积操作分解为两个步骤:先进行逐通道(depthwise)的空间滤波,然后使用1x1的卷积(pointwise)进行通道组合。这种方法大大减少了参数数量和运算量。
在使用Depthwise Conv2D的情况下,即使是资源受限的STM32微控制器也可能能够运行相对较复杂的图像识别网络。这使得在实际应用中,如嵌入式视觉系统或IoT设备中,可以部署更有效的模型。
深度可分离卷积(Depthwise Separable Convolution)之所以能显著降低模型的参数量,主要是因为它将传统的卷积操作分解成两个更简单的步骤:深度卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)。这种分解大大减少了所需的参数数量和计算复杂度。
1. 标准卷积#
首先,让我们理解传统的卷积层是如何工作的。在标准卷积中,每个卷积核都是跨所有输入通道的。这意味着如果你有一个输入特征图(Feature Map)具有C_in个通道,并且你使用C_out个卷积核,每个卷积核的大小为K x K(其中K是卷积核的高和宽),那么你将有:
$$
\text{参数数量} = C_{in} \times K \times K \times C_{out}
$$
这个数量可以非常快速地增长,尤其是在通道数(C_in和C_out)较高时。
2. 深度可分离卷积#
深度可分离卷积通过以下两个步骤减少参数数量:
a. 深度卷积(Depthwise Convolution)#
在这一步中,对于输入特征图的每个通道,我们应用一个单独的
K x K卷积核。这意味着每个通道都独立地进行卷积操作。因此,对于
C_in个通道,深度卷积的总参数数量是: $$ C_{in} \times K \times K $$
b. 逐点卷积(Pointwise Convolution)#
接下来,使用1x1的卷积核(逐点卷积)将深度卷积的结果在通道上进行组合。
对于每个1x1卷积核,你有
C_in个输入通道和C_out个输出通道。因此,逐点卷积的总参数数量是: $$ C_{in} \times 1 \times 1 \times C_{out} = C_{in} \times C_{out} $$
3. 参数量的减少#
将两者相加,深度可分离卷积的总参数数量是: $$ C_{in} \times K \times K + C_{in} \times C_{out} $$ 与标准卷积相比,这显著减少了参数数量,因为在深度卷积步骤中,卷积核是独立于通道的,并且逐点卷积只使用了1x1的卷积核。这种方法在维持相似的表现的同时,显著减少了参数数量和计算复杂度。
使用深度可分离卷积,如在MobileNet架构中所采用的,可以显著减少模型的参数量,通常能达到减少到标准卷积参数量的1/8到1/10。
如何估计一个大规模网络能否部署#
评估一个大规模网络是否可以部署在STM32微控制器上涉及多个方面的考量。STM32是一个资源受限的平台,因此在考虑网络的部署时需要特别关注以下几个关键方面:
1. 内存限制#
- **RAM:用于存储网络的权重、中间计算数据和激活。你需要确保模型的大小加上运行时需要的额外空间不会超过STM32的RAM限制。
- Flash存储:用于持久存储模型本身。模型的总大小需要适合STM32的Flash存储容量。
2. 计算能力#
- 处理器性能:评估模型需要的计算量(如浮点运算数FLOPS)与STM32处理器的运算能力是否匹配。
- 运行时间:确保模型的推理时间满足应用的实时性要求。
3. 功耗要求#
- STM32通常用于低功耗应用。模型运行时的功耗应该符合系统的总体功耗设计。
4. 模型优化#
- 量化:考虑是否可以使用量化(如将float32转换为int8)来减小模型大小和降低计算需求。
- 剪枝和压缩:移除不重要的权重和通道,以减少模型的大小。
- 使用轻量级模型架构:例如MobileNet、SqueezeNet等。
5. 软件支持#
- 框架兼容性:确保模型可以被转换为STM32支持的格式,如TensorFlow Lite for Microcontrollers。
- 操作支持:模型中使用的操作(如卷积、激活函数等)需要TFLite Micro支持。